Going beyond tabulating comentions
In this and my next post, I’ll be showing a a few quick analyses we performed using a new tool we developed, called Elias. In today’s post, we’ll see how topic modeling can be used to characterize how entities are co-mentioned, not just how often.
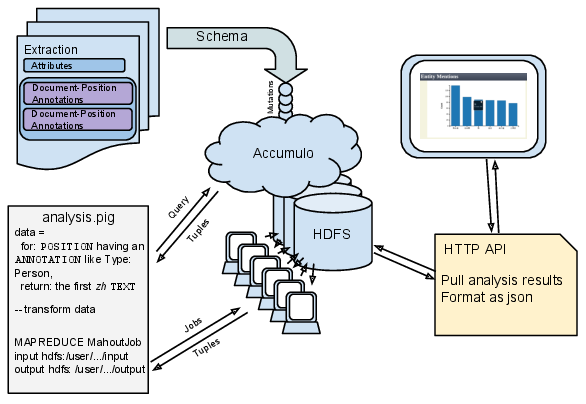
Elias is designed for the exploratory analysis of information extracted from text, when lots of such extractions are available. We take in the results of your favorite Natural Language Processing tools, and store those results in an Accumulo table. Then, an expressive query language lets you pull out just those annotations you are interested in, and write Pig scripts to manipulate the data any way you see fit, including launching Mahout jobs for advanced analytics. Finally, our visualization front end brings the data to life, with additional filtering to help you drill down. This architecture is summarized in the following diagram:
In today’s example analysis, we look at entities mentioned in documents which also mention “Syria.” Our Elias query pulls back all named entity annotations from such documents. This query is directed from within a Pig script, where we also GROUP all pairs of (person,location) occurring in the same sentence and COUNT the number of such occurrences. A natural way to view this data is as a simple comention matrix, like the following, in which we have filtered to a few choice people and locations:
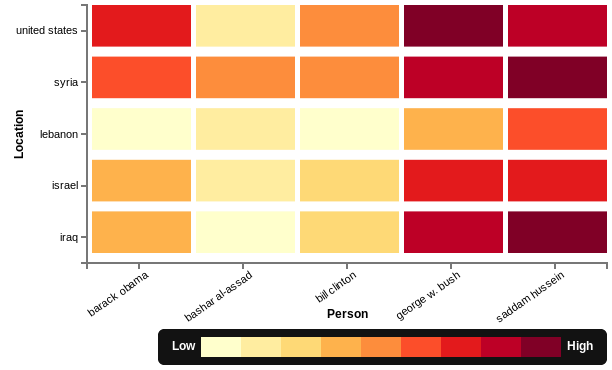
However, this table doesn’t describe how an entity is mentioned with a location. What’s the context when President Obama is mentioned with Syria? Is it different from the context with President Bush, or Bashar al-Assad are mentioned with Syria?
To answer these questions, we use Elias to pull out the text tokens from the containing documents, and push the results through Mahout’s topic modeling algorithms. For each (person,location) pair, we then take the average topic distribution over all containing documents to obtain a topic distribution for the pair. This can be used to classify the pairs in many ways, for example by clustering or choosing the top-weight topic. In the following figure, we have adopted the second approach, so that we can include the top words from the selected topic in tooltips, to more easily compare the contexts. In this figure, color is used to distinguish the categories, and size reveals the number of comentions. We see, for example, that Obama and al-Assad are mentioned in different contexts with Syria (“states” and “security” for Obama, “soviet” and “assad” for al-Assad). We also note that al-Assad’s comentions with Lebanon and Israel stand out (“hezbollah” and “lebanon”) when compared with the other actors (“palestinian” and “israel”).

By enabling exploratory analysis of large-scale information extractions, Elias makes it quick and easy to determine what information exists in your large text corpus.